

Web3 Explained: Part 1 of 2
Web3 Explained: Part 1 of 2
The need for a new generation of internet

Hi friends 👋,
Happy Monday!
A week ago, I sent around a survey to my immediate network with one simple question: “What is it you want to know about Web3?”. I planned to dedicate this very piece to an FAQ-style answering of all the burning questions that followed. But the results of the survey shocked me.
No one filled it out.
Not one person.
So I donned my detective hat and dug deeper into this curiosity. After many texts and calls, the truth came to light: people were so unfamiliar with the idea of Web3 that they didn’t have any questions. Now that is valuable data.
So, behold my response to this revelation. This series is an educational manifesto - designed to act as both a foothold for newcomers and a nuanced all-up review of the fundamental Web3 narrative. This piece in particular sets the stage for why we need a Web3, a story which goes back to the early history of the internet. Welcome to the adventure of the unified Web3 story.
Let’s get to it 🚀
Web3 Explained
The need for a new generation of internet
Before we begin, a quick prelude on learning.
It’s the nature of the world that information arrives reverse-chronologically. We tend to hear of the most recent happenings first. As a result, we are almost always context-deficient. This is a disastrous outcome for our learning because to understand you need to figure out an idea’s ‘why’.
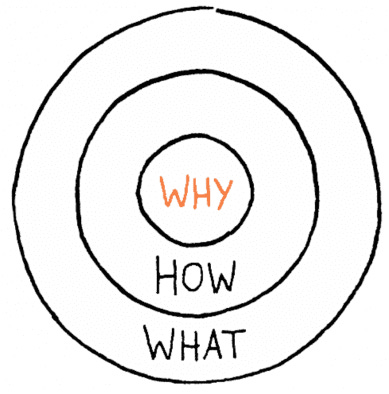
I’m a big fan of Simon Sinek’s What-How-Why circle. Understanding, like narrative, is composed of layered concepts. The WHAT layer is made of events and occurrences; random blips on our radar that don’t paint much of a picture but act as a signal of activity. HOW describes the mechanism, the set of rules and principles that help us recognize patterns and direction. But WHY is where the magic happens. WHY contains the compelling viewpoints and rationale that explain an idea’s purpose in the broader world. WHY is not science, but art. To understand the WHY of Web3, we first must take it back to where it all began.
The evolution of the Web
Nearly everyone reading this article should be familiar with cryptocurrencies, like Bitcoin and Ethereum. Maybe you’ve done the extra reading and are familiar with decentralized finance or NFTs. These are applications of Web3, sitting somewhere between the WHAT and HOW layers.
Web3 in itself is a far greater concept than any one use case. Implied in the name is that it will define a new generation for the internet. This is difficult to understand because we rarely think of the internet as having distinct phases, and instead consider it to be a continuous line of progress. So let’s watch the Web evolve in a matter of minutes, and use history to contextualize the disruption of today.
When the heck did we get to 3?
Most people’s knowledge of the internet is a blurry interpolation between historical events: the Department of Defense funded ARPANET, the dot com bubble rose and fell, somewhere along the way Microsoft got sued… This anecdotal account makes for a good story, but history is about the societal, economic, and ideological influences that manifest these events.
It was in the early 1980s that the backbone of the internet was created. Our foundational development was creating a set of protocols that could let any computer navigate from website to website using hyperlinks.
But hold up, what are protocols? A protocol is a set of rules for formatting or processing data. Computers that use the same protocols send and receive messages in the same format, as though they are speaking in the same language. Now many of the internet’s protocols were designed to be both open and standardized. Standardization means establishing a de facto way of communicating or exchanging data. Open means that any device can join this network of computers simply by using the protocol.
The opposite of an open protocol is a proprietary one. Skype, for instance, has a protocol for voice communications that is not in the public domain. As a result, no one outside of Skype can send or receive Skype calls. Users are locked into the network by design.
And that’s all you need to understand Web1! The earliest version of the internet was built on top of open and standardized protocols. But the idea of open protocols wasn’t just a means to an end, it was a veritable movement. As the internet matured, people were certain the open nature of the internet would continue to its next evolution; Web2. In his piece, The Weird Thing About Today’s Internet, Alexis Madrigal captures this moment in time:
“Web 2.0 was not just a temporal description, but an ethos. The web would be open. A myriad of services would be built, communicating through APIs, to provide the overall internet experience. The web itself, en toto, was the platform, as Tim O’Reilly, the intellectual center of the movement, put it in 2005. Individual companies building individual applications could not hope to beat the web platform.”
The web was viewed as the entity that would fully absorb the value of network effects. Each new website and every new user would add to the web’s unstoppable momentum. It seemed to many like the internet was destined to be open… but we know how that story ends.
Fatal flaws of the open web
While Web1 protocols could define the transfer of necessary communication-level data, there were no effective methods for managing and storing user data. When applications maintain a set of information about their users and activity, this is known as capturing an application’s ‘state’. As a result, Web1 protocols were stateless. Websites had no way to determine who was visiting their site or if they’d had any prior interaction with Web1 users.
We’ve all encountered internet cookies before. Well the entire system of cookies is actually a work-around to the problem of a stateless internet. Cookies fly around the internet as text files that store data to help websites identify you, and associate you with other useful pieces of information. Even today, websites can only recognize users via their cookies.
While the state problem was fatal in its own right, the early internet had other birth defects. Web1 was missing protocols for many functional areas like payments, search, and social media. So where the open web lacked functionality, markets rose to create their own solutions. Companies like Facebook, Twitter, Google and Stripe filled in the protocol gaps with proprietary code. This was an implicit competition to define the next generation of the internet. Web2 stood to be defined by either proprietary or open source development.
Despite the effort of the open internet’s keyboard warriors, the process of building new open protocols was filled with friction. Defining new standards for the web involved mass coordination across stakeholder groups, requiring multiple phases of review and prototyping. On the flip side, any company could simply create an internal solution to any of Web1’s technical shortcomings. Chris Dixon describes this advantage well:
“As a result, proprietary services were able to create better user experiences and iterate much faster. This led to faster growth, which in turn led to greater investment and revenue, which then fed back into product development and further growth. Thus began a flywheel that drove the meteoric rise of proprietary social networks like Facebook and Twitter."
It’s worth pausing here to emphasize that the early internet was caught between two ‘camps’ of software development theory: the open source movement and the rise of proprietary development. As history shows, proprietary development proved to be a far superior method for advancing the internet.
Where Web1 struggled with the state problem, it was easy for Web2 companies to use centralized databases. The proprietary flywheel established huge economic value on top of a version of the internet powered by private code repositories. Even at this point, debate still raged about whether the open source rebellion could push back. It was the mobile revolution that put the final nail in the open web’s coffin. Post-mobile, people’s view of the internet increasingly became app-centric. In a matter of years, digital experiences were mostly contained inside centralized apps, and people’s engagement with the open web reduced dramatically.
With the final bell rung, Web2 became defined by the progress of proprietary networks. This privately owned internet exploded into the age of online abundance that we exist in and benefit from now. There’s no sign that the march of proprietary development will slow, as the lever of technology becomes more powerful by the day. Our lives have measurably improved from the innovations brought by Web2. This, of course, begs the question - why do we even need a new generation of internet?
The need for Web3
Any analysis of the web’s next evolution will demand that we call out weaknesses and areas for improvement in the current internet. Indeed, this argument is a delicate balance between acknowledging Web2’s contributions and scrutinizing its shortcomings.
It’s important to note, that there will be no wholesale replacement of Web2. HTTP is still foundational to how we experience the internet just as email remains a pillar of communication. But just as the proprietary Web2 addressed the problems of the early open internet, we must work to ‘find the gaps’ and understand what opportunity there is for a new generation.
First, the good: Today’s internet companies are training grounds for generations of our greatest builders and thinkers. Their success creates an economic incentive for people to become technically literate. Web2 products have defined the current era of online collaboration: multi-user document editing, shared code repositories, teleconferencing, digital collaboration spaces like Discord and Slack. Web2 makes the world feel smaller, allowing distant strangers to connect over shared interests - ironically, even including those who aim to work on Web3.
Now, for what can be improved. In my opinion, there are three major flaws with our current internet.
The entire internet experience is vastly defined and controlled by a handful of mega-cap companies.
Excessive success reduces competition at nearly every layer of the internet value chain.
The current internet is defined by platforms that subscribe to a value-locked-in paradigm
The dilemma of borrowed distribution
Over the past year, it’s become more obvious that internet users aren’t so much inhabiting their digital spaces, as they are renting them. It’s the major internet companies that ‘own the rails’ and choose what content - and even which users - can live on their platforms. We know this as the issue of censorship, but censorship is a side-effect of relying on a minority of companies to curate the internet experience.
Podcaster Tim Ferriss is fond of quoting his friend who owned a million dollar business built out on a Facebook page. He’d say:
“Well, it’s going great, but it feels like I have the most profitable McDonald’s in the world built on top of an active volcano”.
That’s funny, until you realize that the volcano is a metaphor for Facebook’s ability to change their algorithm. You might spend years generating free content and developing a relationship with your audience, and then one day you need to buy ads to reach them. As Chris Dixon mentions in Why Decentralization Matters, this is not paranoia, but rather the logical order of operations for businesses.
In the beginning of their life cycle, platforms create value by attracting users and partnering with complementary companies. The platform’s goal is to encapsulate and support a vibrant ecosystem of online activity. This is the bottom of the S-curve in the graphs below. Companies still have much to gain by bringing users and 3rd-party solutions into the fold. But in the long run, this strategy offers diminishing returns. Eventually companies reach an inflection point when cooperation is no longer the best path to capture value.
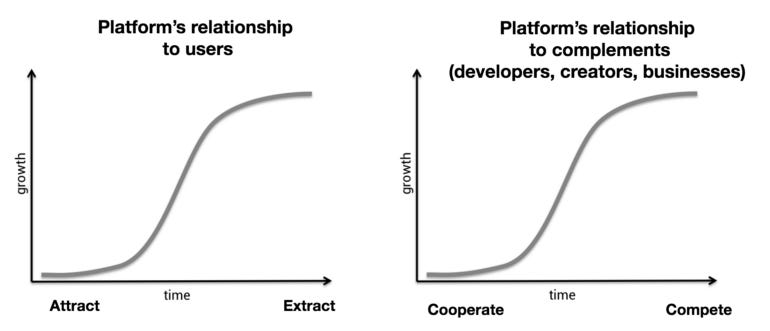
As described in the article:
“When [companies] hit the top of the S-curve, their relationships with network participants change from positive-sum to zero-sum. The easiest way to continue growing lies in extracting data from users and competing with complements over audiences and profits. Historical examples of this are Microsoft vs. Netscape, Google vs. Yelp, Facebook vs. Zynga, and Twitter vs. its 3rd-party clients.”
Companies are first and foremost economic agents. Their prime directive is to increase shareholder value. The dilemma of borrowed distribution is that the profit motive is not inherently evil, but can at times be fundamentally misaligned with the values of users.
The blunting of competitive edges
While all software companies benefit from low capital costs, it’s really the winners who can take off into orbit. Once a high-margin product achieves a certain economy of scale, cash flows can be wholly used to build out the future.
Often this future means capturing more of the value chain with increased, multi-market product offerings. A consequence of this is that companies ‘featurize’ entire product categories simply to add another feather to the cap of their flywheel. Consider what Twitter Spaces did to Clubhouse, or what Apple Music is trying to do to Spotify. Even Netflix executives must be sweating with Amazon and Apple dropping billions into TV and film content. When these product lines don’t translate to significant revenue opportunities, they become stagnant layers in the value chain. Did anyone catch the latest Gmail update? Neither did I.
What we want is more brains, resources, and talent on every problem - at every layer of the value chain. We want users to vote on the best solutions with their time and money. This can’t be done when products are excessively bundled and companies are willing to soak the costs of ‘necessary’ product lines. It’s a problem when young entrepreneurs plan company roadmaps towards being acquired by one of today’s giants.
The inescapable gravity of centralization
In software, value capture is often a function of data capture. Data is the fundamental resource that companies use to know more, do more, and become more. The nature of a proprietary stack means that a company’s window into the internet is limited to what can be stored on their servers. As a result, there is very little incentive for companies to pursue integrations, when instead they can expand. This is why we find ourselves on monolithic platforms offering full-stack services.
This leads to the problem of walled gardens. Any value you create on a platform is locked into existing on company servers. Forget storing your medical records in one place, you can’t even transfer a Spotify playlist to Apple Music! Web2 built the internet on top digital islands, and neither users or data can cross from shore to shore.
Looking to the future
It’s clear that modern companies are the winners of Web2. But the features that cemented the proprietary web’s victory also define its shortcomings. In the name of growth, companies are resorting to value-extractive practices, claiming ever-growing chunks of the internet. As these platforms increase the scope of their borders, they exert an inescapable pull on users and their data.
While regulation is catching up to this dilemma, it’s clear we can’t get out the same way we got in. The next generation of the internet will need to find ways to overcome the competitive moats of modern giants, all while offering users the quality of experience they’ve grown accustomed to.
We now live at an interesting point in time. Collaboration on the internet has never been easier. The public is far more technically proficient than they were in the 1980s. Could it be that the scales are tilting in favor of the open web?
Indeed, the leading model for Web3 is a return to Web1’s values. A digital experience governed by open protocols. A network of networks where both data and users traverse the internet fluidly. Blockchain, tokens, NFTs - these are new primitives for a digital world where users, not companies, are the focal point of value.
What’s left for us is to define Web3. Next week we’ll take the plunge and understand how these shifting technologies work together in harmony to create the next-generation of the internet.
What a beautiful and exciting world to live in.
If you enjoyed this article consider subscribing for weekly content on the technology that will shape our future!
If you really enjoyed this article consider sharing it with an intellectually curious friend or family member!
Let me know what you thought about this piece on Twitter.
With gratitude, ✌️
Cooper
Great article, really well explained
Very thorough and informative..well done.